

I’m currently going through an archive of my old dead blog trying to resurrect old posts that may still be useful, this is one from January 2014 talking about testing backups:
I have recently moved to HP’s Advanced Technology Group which is a new group in HP and as part of that I will be blogging a lot more about the Open Source things I and others in HP work on day to day. I thought I would kick this off by talking about work that a colleague of mine, Patrick Crews, worked on several months ago.
For those who don’t know Patrick, he is a great Devops Engineer and QA. He will find new automated ways of breaking things that will torture applications (and the Engineers who write them). I don’t know if I am proud or ashamed to say he has found many bugs in code that I have written by doing the software equivalent of beating it with a sledgehammer.
Every Devops Engineer worth his salt knows that backups are important, but one thing that is regularly forgotten about is to check whether the backups are good. A colleague of mine from several years back, Ian Anderson, once told me about the hunt for a good tape archive vendor. He tested them by getting them to pick a randomly selected tape from the archives and reading it, timing how long it takes to do so. You would be surprised the vendors who couldn’t perform this task, I’d hate to see what would happen in a real emergency.
There was also the case of CouchSurfing which was crippled back in 2006 when after a massive failure they found their backups to be bad. They eventually rebuilt and is a great site today, but this kind of damage can cost even a small company many thousands of dollars.
The main thing I am trying to stress here is that it is important not just to make backups but also to make sure the backups are recoverable. This should be done with verification and even fire drills. There may come a time where you may really need that backup in an emergency and if it isn’t there, well you just burnt your house down.
Before I was a member of the Advanced Technology Group I was the Technical Lead for the Load Balancer as a Service project for HP Cloud. We had a very small team and needed a backup and verification solution that was mostly automated and reliable. This thing would be hooked up to our paging system and none of my team like being woken at 2AM 🙂
This is a very crude diagram of the solution Patrick developed:
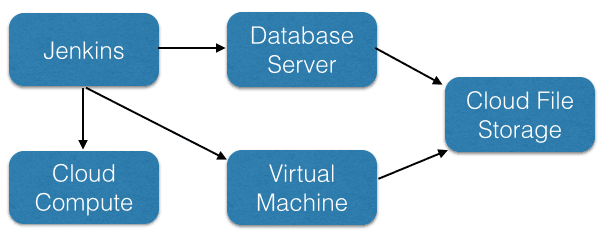
The solution works as follows:
- Every X minutes Jenkins will tell the database servers to make a backup
- The MySQL database servers encrypt that backup and push it up to the cloud file storage (Openstack Swift)
- Jenkins would then trigger a compute instance (Openstack Nova) build and install MySQL on it
- The new virtual machine would grab the backup, decrypt it, restore it and run a bunch of tests on the data to see if it is valid
- If any of the above steps failed send out a page to people
Most of the above uses salt to communicate across the machines. Have we ever been paged by this system? Yes, but so far only because step 3 failed, either due to a Nova build fail or once due to a salt version incompatibility. We have since added some resilience into the system to stop this happening again.
As well as the above there are monthly fire drills to manually test that we can restore from these backups. We also regularly review the testing procedures to see if we can improve them.
This is going to sound a little strange but sometimes the best Devops Engineers are lazy. By that I don’t mean they don’t do any work (they are some of the hardest working people I know), but they will automate everything so they don’t have to do a lot of boring manual labour and they hate being woken by pagers at silly hours of the morning. Some of the best Devops Engineers I know think in these terms 🙂
Leave a Reply